常见问题
内存占用太大?可以试试使用量化模型
如果你在使用闪电说时,发现 内存占用偏高 ,这通常是因为默认使用的是 非量化(原始精度)模型 。
如果你在使用闪电说时,发现 内存占用偏高,这通常是因为默认使用的是 非量化(原始精度)模型。
你可以手动更换为 量化版本模型,体积更小、运行更轻量、内存占用更低。
⚠️ 注意:量化模型会更省内存,但精度会有一定下降。 如果你对识别准确率要求非常高,建议继续使用默认模型。
下面只需要 三步 即可完成。
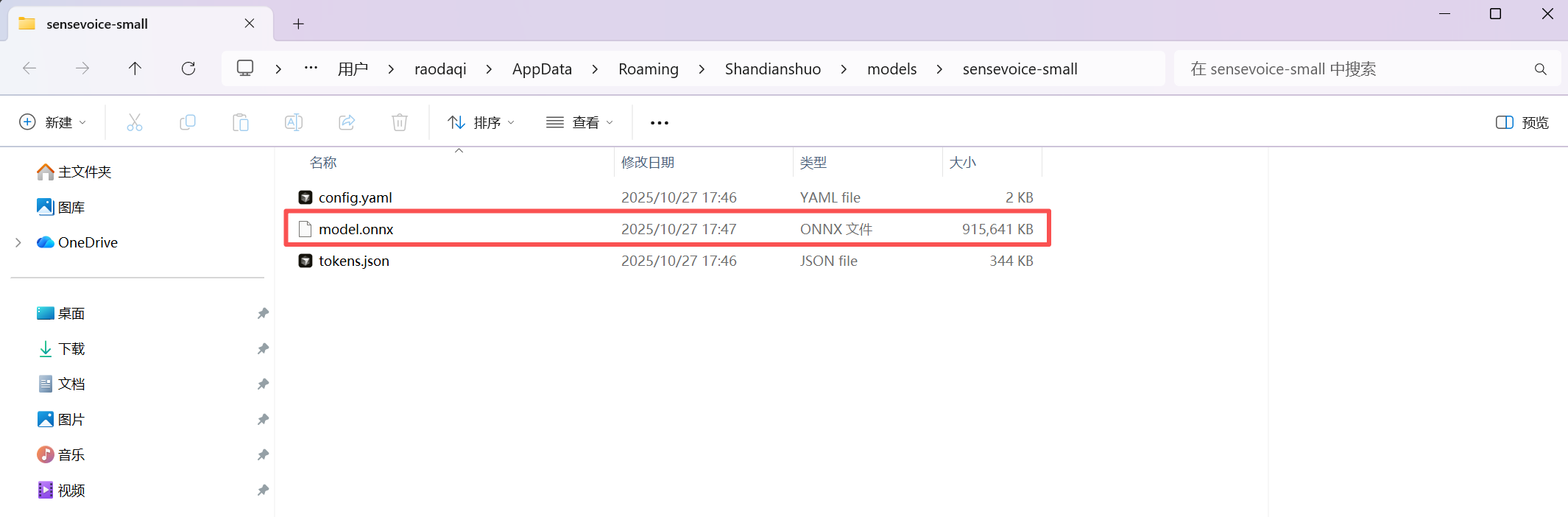
第 1 步:下载量化模型文件
请在这里下载SenseVoice 量化模型文件model_quant.onnx:
👉 下载地址:SenseVoice多语言语音理解模型Small-onnx · 模型库
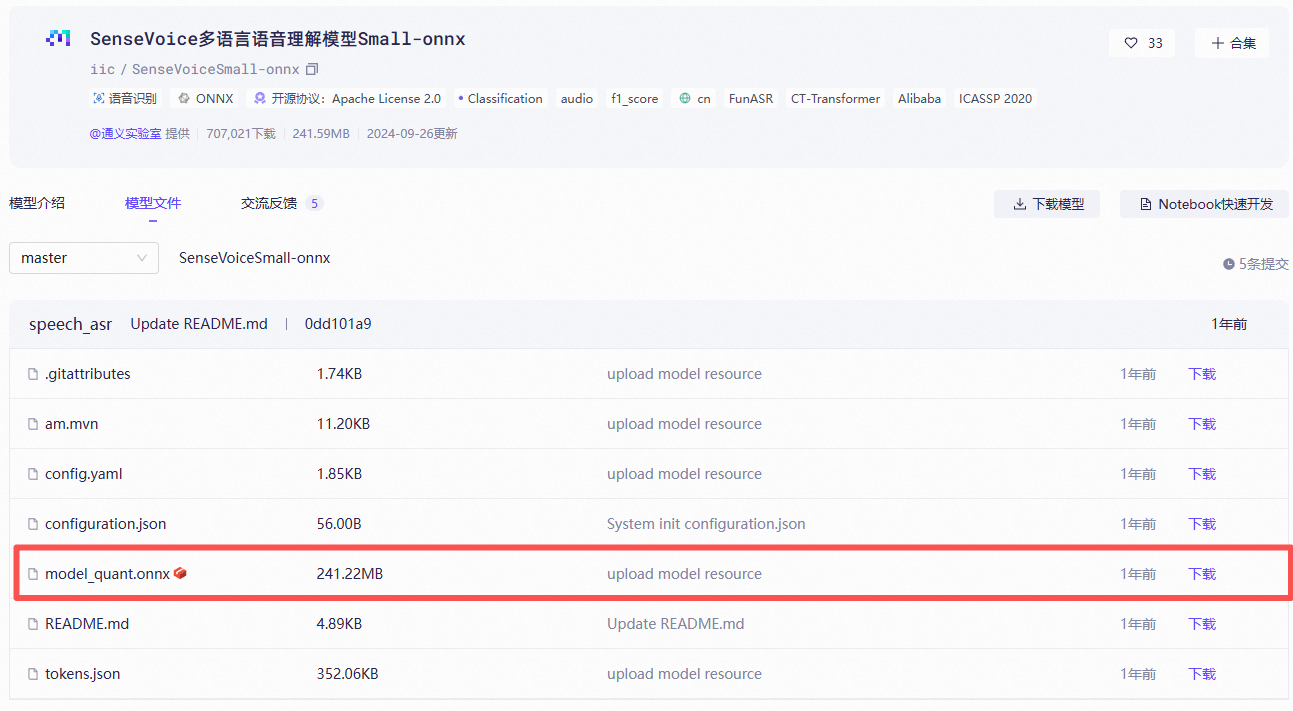
第 2 步:打开闪电说的模型目录
- 打开闪电说
- 点击设置
- 找到 「模型设置」
- 点击 「打开目录」 按钮
- 点击后会自动打开模型文件所在的本地目录
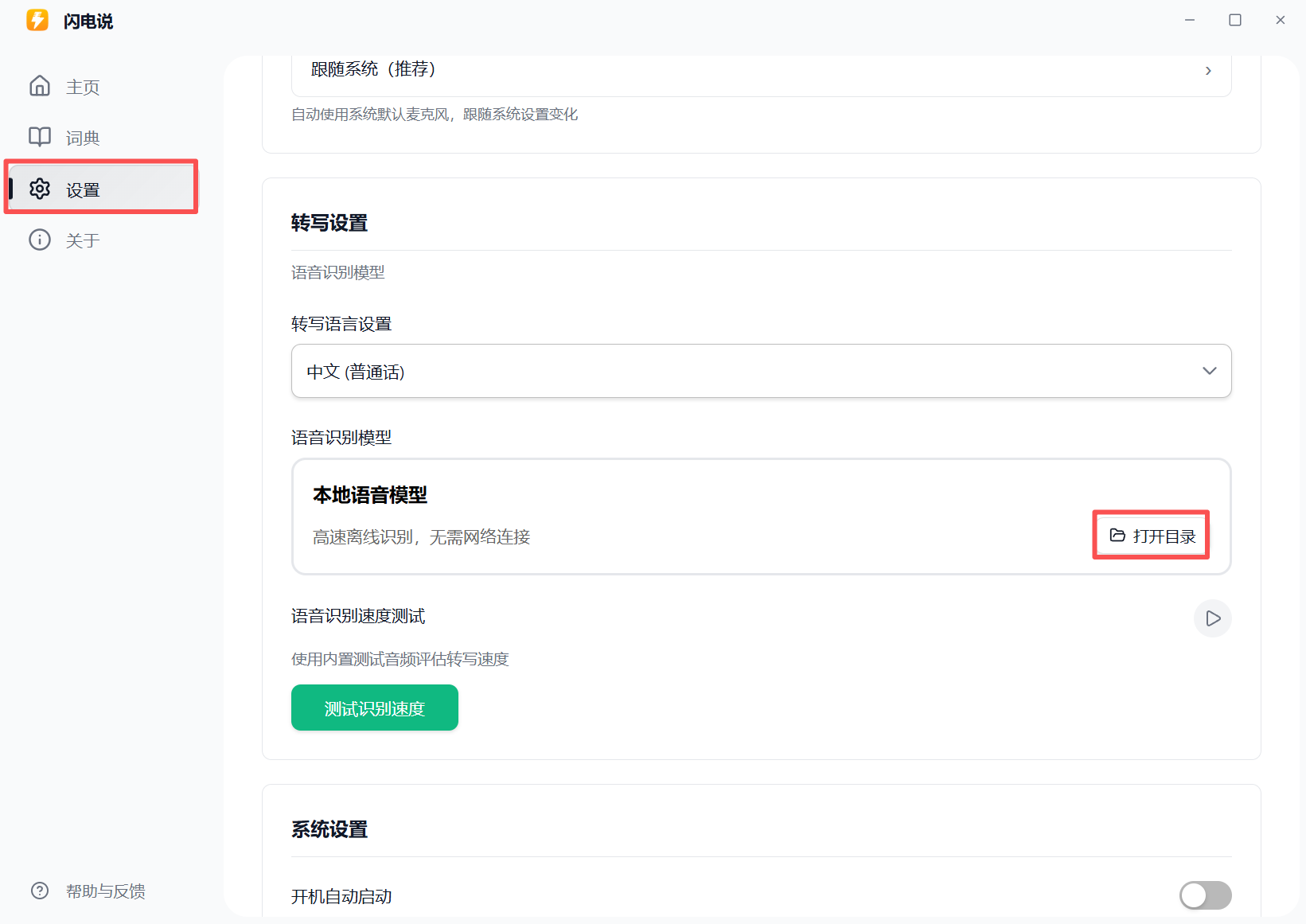
第 3 步:替换模型
-
备份或删除原来的模型文件
-
将下载的量化模型 model_quant.onnx 更名为 model.onnx
-
将更名后的量化模型替换目录原来的模型文件
-
重新启动闪电说即可生效
完成!
更换为量化模型后,你将获得:
- ✔ 更低的内存占用
- ✔ 更快的启动速度
- ✔ 更轻的 CPU/GPU 压力
同时请注意:
- ✦ 精度会略有下降,尤其在噪音环境或口音较重时
- ✦ 如果对准确度非常敏感,可以随时换回默认模型